改造レバーレスの基板を換装した (組み立て編)

改造レバーレス基板換装メモの組み立て編です。その他のメモは以下を参照してください。
- 改造レバーレスの基板を換装した (作業計画編) - garbagetown
- 改造レバーレスの基板を換装した (基板準備編) - garbagetown
- 改造レバーレスの基板を換装した (外装加工編) - garbagetown
- 改造レバーレスの基板を換装した (配線準備編) - garbagetown
- 組み立て
買い物リスト
これまで準備したものを組み立てるために次のものを買いました。
| 物品名 | 購入先 | 単価 (円) |
|---|---|---|
| タカチ電機工業 AST3-6B ナット入り貼付型スペーサー ASTシリーズ | 千石電商 | 230 |
| プラダン | セリア | 100 |
プラダンはカッターで簡単に切れるプラスチック製の段ボールのような素材です。F500 とネジ位置が違う PFB を取り付けるために使います。強度は頼りないですが、負荷がかかる場所ではないので簡単に加工できる点を重視しました。
組み立て
F500 の基板を取り外し、PFB 右側の USB-C ケーブルや下側の 4 ピンコネクタが外装に干渉しないように設置できる場所を探します。おおよその位置が決まったら PFB と同じ大きさにカットしたプラダンを押し当てて、ネジ位置にキリで穴を開けます。プラダンが半透明なためネジ位置が見えやすくてよかったです。

プラダンを外装にネジ止めします。なお、各ボタンはすでに配線済みです。

両面テープ付きのスペーサーを貼り付けます。スペーサーを貼り付ける位置の関係からプラダンを止めている右側 2 箇所のネジにアクセスできなくなりますが、取り外す予定はないですし、いざとなったら破壊すればいいと割り切りました。

PFB をネジ止めします。

各ボタンのケーブルをターミナルブロックの所定のピンに挿し込んだら、ネジを締めて固定します。パススルー用のケーブルも端子付き USB ケーブルに挿し込んでネジで固定します。

最後に USB-C ケーブルを接続して完成です。右上の基板の TURBO ボタンが使われておらずもったいないことに気づいたので、トレーニングモードの再スタートなどに便利な LS ボタンに割り当てました。PH コネクタ付きケーブルを取っておいてよかったです。

背面に移設した USB ポートに RAP.V を、PFB に接続した USB-C to A ケーブルを PS5 に接続して、認証をパススルーできていることを確認しました。

余談
ボタンをつけたり外したりしているうちにツメが折れてしまいました。ひとつ 450 円もするクリアボタンなのでけっこうショックでした。

ひとつ 240 円のボタンに交換しようと千石電商に足を運びましたが、無難な白や黒、グレーは欠品だったため、今回はクリアボタンのグレーに変更してみました。

ホールソーで空けた穴が少し小さめで、ツメを強く押し込まないと外せなかったことが原因と考えられます。後日、ステップドリルビットで穴を少し広げる予定です。
まとめ
けっこう入念に下調べした甲斐があり、致命的なミスや見落としなどに見舞われることなく無事に基板を換装することができました。インターネットに知見を公開してくださっている先人たちと、職場のなんでも知っているおじさんに心より感謝します。
今後は必要に応じて L2 ボタンを復活させたり、RS ボタンを増設してみたいと思います。
改造レバーレスの基板を換装した (配線準備編)

改造レバーレス基板換装メモの配線準備編です。その他のメモは以下を参照してください。
- 改造レバーレスの基板を換装した (作業計画編) - garbagetown
- 改造レバーレスの基板を換装した (基板準備編) - garbagetown
- 改造レバーレスの基板を換装した (外装加工編) - garbagetown
- 配線準備
- 改造レバーレスの基板を換装した (組み立て編) - garbagetown
買い物リスト
配線を準備するために次のものを買いました。このほかに、基板準備編に書いた AWG24 ケーブルも使います。
| 物品名 | 購入先 | 単価 (円) |
|---|---|---|
| アイウィス(IWISS) 精密同時圧着ペンチ ラチェット式 オープンバレル端子 0.25〜1.5mm2小・中型端子対応 SN-58B | Amazon | 2,080 |
| オーディオファン 平型端子 110 サイズ メス 50セット | Amazon | 933 |
| JST型(PHR)4Pコネクタ付きケーブル | 千石電商 | 80 |
4P コネクタ付きケーブルは事前の検討が不足していたために買いました。詳細は後述します。
撤去
Mayflash F500 (以降、F500 と略記) の基板を改めて確認します。

作業計画編では次のように書きました。
中央上にある START ボタンと移動および攻撃ボタンからそれぞれ二本ずつケーブルが伸びており、F500 の PH コネクタに接続されています。つまり、各ボタンごとに GND が必要です。PFB 上部に実装されたターミナルブロックには各ボタンに対応したピンがあるものの、GND は 4 つしかないので、チェーン配線にした GND ケーブルを用意する必要があります。
PFB のターミナルブロックには SELECT, HOME (PS) も用意されていますが、TPAD は PFB 下部に 4 ピンコネクタのピン番号 20 として用意されています。購入予定の PFB にはベース付きポストも実装されているので、ハウジングだけ用意すれば良いです。
(省略)
最後に PS5 と接続する USB ケーブルを考えます。F500 のケーブルはメイン基板に 5 ピンコネクタで接続されている一方、購入予定の PFB には USB-C ポートが実装されています。既存ケーブルを加工して USB-C 端子を取り付ける方法も検討しましたが、USB-A から USB-C への変換などがむずかしそうに思えたため、既製品を購入することにしました。
START と移動および攻撃ボタンからケーブルを一本ずつ、右上の基板から SELECT, HOME, TPAD, GND ケーブルを流用し、そのほかは撤去します。

いつか PH コネクタが圧着されたケーブルが必要になるかもしれないので、ハウジングから引き抜いておきました。

右上の基板も一時的に取り外して不要なケーブルを引き抜いておきます。

4P コネクタ付きケーブルを買った時点では、ハウジングから PH コネクタ圧着済みのケーブルを引き抜くという発想がありませんでした。また、ファストン端子を圧着するために購入した SN-58B で PH コネクタを圧着できるか判断できませんでした。このため、TPAD ケーブルを次のように接続しようと考えていました。
F500 -> TPAD ケーブル (PH コネクタ切断、ファストン端子オス圧着) -> 4P コネクタ付きケーブル (ファストン端子メス圧着) -> PFB
その後、ハウジングから PH コネクタ付きのケーブルを引き抜いて次のように配線すれば良いことに気づきました。
F500 -> TPAD ケーブル (PH コネクタ圧着済み) -> 4P ハウジング -> PFB
このような経緯で購入した 4P コネクタ付きケーブルから不要になったケーブルを引き抜きます。ついでに PFB ではパススルー用 USB ケーブルに 5V を供給できないため不要になっていたケーブルも引き抜いておきます。

被覆剥き
F500 から流用するケーブルには、いずれもメイン基板に配線するための PH コネクタが圧着されています。PFB ではターミナルブロックに配線するので、PH コネクタを切断してから被覆を剥いて芯線を露出させます。次の写真の上側が PH コネクタが圧着されているもの、下側が PH コネクタを切断してから被覆を剥いたものです。

ワイヤーストリッパーを購入しなくてもニッパーでなんとかなるだろうと考えていましたが、力が弱ければ被覆が切れず、強ければ芯線ごと切断してしまい、予想以上にむずかしかったです。インターネットで見つけたラジオペンチとニッパーで代用する方法を試したところ、簡単かつきれいに被覆を剥くことができて、とても助かりました。
圧着
最後にチェーン配線にした GND ケーブルを作ります。先に完成したものを見たほうが分かりやすいと思います。間違えて両端にもファストン端子を圧着してしまいましたが、後述する通り片方はターミナルブロックに配線するので端子を圧着する必要はありませんでした。

アケコンのボタンは電子回路のスイッチです。ボタンを押すことで回路が閉じてゲーム機に信号が送られます。F500 の場合、例えば START ボタンと弱 P ボタンは次のよう配線されていました。
START 信号ピン -> START ボタン -> START GND ピン 弱 P 信号ピン -> 弱 P ボタン -> 弱 P GND ピン
冒頭に引用したとおり PFB には各ボタンごとの GND ピンは用意されていません。また、GND ピンは電圧をゼロにするためのものであり、共用できます。つまり、次のように配線しても動作します。
START 信号ピン -> START ボタン -> 共用 GND ピン 弱 P 信号ピン -> 弱 P ボタン -> 共用 GND ピン
各ボタンから同じターミナルブロックに配線する方法も考えられますが、ボタン数が多いのですべてのケーブル芯線をより合わせると太くなり過ぎてターミナルブロックに挿さらないおそれがあります。そこで、次のように各ボタンの端子を渡り歩いて最終的に同じ GND ピンに辿り着くようにチェーン配線したケーブルを作るわけです。
START 信号ピン -> START ボタン -> 弱 P ボタン -> 中 P ボタン -> (省略) -> 上方向ボタン -> 共用 GND ピン 弱 P 信号ピン -> 弱 P ボタン -> 中 P ボタン -> (省略) -> 上方向ボタン -> 共用 GND ピン
START 以外のボタンは両隣のボタンと GND ケーブルで配線する必要があるので、ひとつのファストン端子に 2 本のケーブルを圧着することになります。まず、上述の要領で被覆を剥いたケーブルを 2 本用意し、芯線をより合わせます。

これにファストン端子を圧着します。確実に信号が流れるように金属同士を圧着させる部分と、端子が抜けないように被覆を圧着させる部分の 2 箇所をかしめる必要があります。

この 2 箇所を同時にかしめてくれるのが IWISS SN-58B です。AWG24 のケーブルを 2 本束ねて圧着する場合は 1.0 のダイスが使いやすかったです。ダイスにファストン端子を乗せてカチカチと 2 回鳴るまでゆっくり握ってダイスに端子を固定します。

ここにケーブルを挿し込んでかしめるわけですが、ラチェット式の圧着工具は 2 箇所を同時にかしめるためダイスの幅が広く、ケーブルを適切な位置に挿し込めているか視認しづらい欠点があります。そこで予備のファストン端子にケーブルを当てがい、ここまで挿し込めば良いという位置までファストカバーを引き上げて、ズレないようにしっかり握ってから圧着工具に挿し込む方法を考えました。

ファストンカバーが圧着工具に押し当たる位置までケーブルを挿し込んだら、圧着工具をしっかり握ってかしめます。最後まで握るとロックが解放されて端子を取り出せるようになります。ファストン端子側の 2 箇所の金属が芯線と被覆にしっかり食い込んでいれば圧着成功です。

これですべての準備が整いました。次は組み立てについて書きます。
改造レバーレスの基板を換装した (外装加工編)

改造レバーレス基板換装メモの外装加工編です。その他のメモは以下を参照してください。
- 改造レバーレスの基板を換装した (作業計画編) - garbagetown
- 改造レバーレスの基板を換装した (基板準備編) - garbagetown
- 外装加工
- 改造レバーレスの基板を換装した (配線準備編) - garbagetown
- 改造レバーレスの基板を換装した (組み立て編) - garbagetown
買い物リスト
外装を加工するために次のものを買いました。
| 物品名 | 購入先 | 単価 (円) |
|---|---|---|
| 簡易ノギス | ダイソー | 100 |
| ステップドリルビット | メルカリ | 750 |
Amazon で見つけたパネルマウント USB ソケットのページには寸法が書かれていなかったので、まず簡易ノギスを買って寸法を測りました。

外装に 22mm の穴を空ければ良さそうです。

ネジ穴は 3mm でした。

天板を加工する際にメルカリで買ったホールソーには 22mm の刃がありません。20mm の穴を空けてから丸棒ヤスリで広げるのは大変そうです。

そこで同じくメルカリでステップドリルビットを買いました。

電動ドライバーと 3mm のドリルビットは在宅勤務環境を整えたときに買ったものを使います。詳細は以下を参照してください。
余談になりますが、ドリルビットやホールソーなどはメルカリに新品が安く大量に出品されているので、必要になった際にはチェックしてみることをお勧めします。
また、前回に書いたようにパネルマウント USB ソケットが 1,213 円と意外に高価でした。割高に感じたのでメルカリや秋葉原を探し回りましたが、お買い得な商品は見つけられませんでした。AliExpress で 300 円程度で販売されているのを見つけましたが、アカウントを持っていないこと、配送に時間がかかること、送料が高いことから今回は断念しました。
加工
必要なものが手元に揃ったので、実際に外装を加工します。外装の内側には補強があり、USB ソケットを当てがってみたところギリギリ入りそうでした。

穴空け位置が左右どちらに寄っても補強を削り取ることになり大変そうです。中心が分かるように慎重にマスキングテープを貼ってから穴空けしたい位置にボールペンで印を付けて、3mm のドリルビットで下穴を開けました。

あとは 22mm のステップドリルビットに交換して穴を広げていきます。細かい削りクズが出るのでベランダで作業しました。20mm くらいまでは一気に広げて、そのあとは USB ソケットが入るようになるまで少しずつ穴を広げました。バリを取るために適当にヤスリがけしたので傷だらけになっていますが、内側なのできれいに仕上げる必要はないでしょう。

逆側からの写真を撮り忘れたので分かりづらいですが、USB ソケットが入ったらそのままネジ穴に 3mm のドリルビットを突っ込んでネジ用の穴を開けます。

ネジが通ったらナットで固定して完了です。穴空けがほんの少しだけ向かって左側に寄ってしまい、右上のナットは素直に固定できましたが、左下のナットはネジを通してから回すと補強に干渉してしまいました。そこで、先にナットを外装に押しつけてからネジを挿し込み、ナットとネジが噛み合ったことを確認してからドライバーで締め込みました。

外装の外側から見た様子です。想像していた通りに仕上がって満足です。

余談
2021-01-14 に次のように書きました。
電動ドライバーを購入するのは初めてなので他の製品と比較できませんが、問題なく使えています。
勢い余ってドリルビットのセットも買いましたが、後日ダイソーで 2.5 mm のドリルビットを発見して悔しかったので今後も無駄に穴を開けたいと思っています。
電動ドライバーとドリルビットセットは、今回の他にも PS5 をデスク天板裏側に固定したり、アクリル天板に穴を空けたりと大活躍しています。良い買い物をしました。
外装の加工については以上です。次回は配線の準備について書きます。
改造レバーレスの基板を換装した (基板準備編)

改造レバーレス基板換装メモの基板準備編です。その他のメモは以下を参照してください。
- 改造レバーレスの基板を換装した (作業計画編) - garbagetown
- 基板準備
- 改造レバーレスの基板を換装した (外装加工編) - garbagetown
- 改造レバーレスの基板を換装した (配線準備編) - garbagetown
- 改造レバーレスの基板を換装した (組み立て編) - garbagetown
買い物リスト
基板を準備するために次のものを買いました。千石電商のレシートは捨ててしまったので、せんごくネット通販で調べた価格を書いています。Amazon の単価は購入当時のものです。この他にも予備や間違えて買ったものもありますが、割愛します。
| 物品名 | 購入先 | 単価 (円) |
|---|---|---|
| Pico Fighting Board | メルカリ | 3,037 |
| 白光(HAKKO) PRESTO 急速加熱はんだこて 20/130W(スイッチオン時) 耐熱キャップ付き 984-01 | Amazon | 2,055 |
| 白光(HAKKO) ペンシル こて台 FX-600/FX-601/PRESTO/DASH用 FH300-81 | Amazon | 742 |
| 白光(HAKKO) HEXSOL 巻はんだ 精密プリント基板用 20g | Amazon | 371 |
| USB-A to USB-C ケーブル L字型 | Amazon | 848 |
| USBタイプA 2.0オス - 5ピンネジ端子メス | Amazon | 639 |
| USB 3.0 TO USB 3.0 メスパネルソケット | Amazon | 1,213 |
| AWG24 耐熱ビニル絶縁電線 2mX7色 | Amazon | 668 |
| PHコネクタ ベース付ポスト サイド型 4P | 千石電商 | 42 |
| JST型(PHR)4Pコネクタ付きケーブル | 千石電商 | 80 |
今回の目玉なので基板の値が張るのはいいとして、やはりはんだ付けに関連する物品の値段が目立ちます。前回に書いた通り、メルカリで見つけた基板にはパススルーに使うピン番号 27, 28 に接続するベース付きポストが実装されていないためです。
BOOTH でパススルー用の USB ポートまで実装された基板が 5,100 円で販売されていましたが、メルカリの売上金が少し残っていましたし、はんだ付けに興味があったので、今回はメルカリで販売されていた基板を使うことにしました。
はんだこてはとても悩ました。有識者にアドバイスを求めると皆が口を揃えて HAKKO FX600-02 のような温度調整機能付きのものを勧めてくれるのですが、基板よりも高く、なかなか手を出せません。
 ダイヤル式温度制御はんだこて FX600-02")
一方で信じられないくらい安い入門セットもたくさん販売されていましたが、110V/60W という謎のスペックで、家庭用電源が 100V の日本でまともに使えるのかよく分かりませんでした。
数時間悩んだ結果、信頼の HAKKO が販売している入門モデルを買うことにしました。
 PRESTO 急速加熱はんだこて 20/130W(スイッチオン時) 耐熱キャップ付き 984-01")
 ペンシル こて台 FX-600/FX-601/PRESTO/DASH用 FH300-81")
糸はんだは後日ダイソーで売っていたのを見つけたので、もう少し節約できたかもしれません。
 HEXSOL 巻はんだ 精密プリント基板用 20g FS407-01")
ベース付きポストの実装
以上の経緯で、ほぼ人生初と言っていいはんだ付けに挑戦しました。中学生か高校生の頃に図工で体験したような気もしますが、なにも覚えていないので YouTube ではんだ付け関連の動画を多数視聴しました。イチケンさんの動画がとても分かりやすいです。
まずは秋月電子で買った 1 枚 80 円の 2mm ピッチ基板で練習しました。少しはんだが多いですが、本格的な老眼が始まりつつあるおじさんの習作として及第点でしょう。

いよいよ本番です。右下の OPT BUTTONS と印字された場所にベース付きポストをはんだ付けします。

ひっくり返してはんだ付けするときに部品が落ちないようにマスキングテープで仮止めします。

はんだこてを当てたときに部品がズレないようにカッティングボードに固定します。

向かって左側が自分ではんだ付けしたベース付きポストです。一番右側のピンのはんだが多いですが、となりのピンにブリッジしていないように見えるので問題なさそうです。

ビビり散らかしていたわりには比較的うまくはんだ付けできてうれしいので、無駄に完成画像を掲載しておきます。

ファームウェアアップデートと設定
メルカリで購入した基板の説明には次のように書かれていました。
◆GP2040-CE_0.7.2_PicoFightingBoard.uf2 インストール済
※初期Input modeはXinputで発送致します
◆SOCDモード
←→N、↑↓Nは標準設定済みです
PS パススルーは 0.7.4 で実装された機能なので、ファームウェアをアップデートする必要があります。また、入力モードも PS4 に変更しておきます。脳内垂れ流しさんの記事がとても参考になりました。
BOOT ボタンを押しながら、いつの間にか我が家に生えていた Windows 11 端末に接続します。ダウンロードしたファームウェアをコピーすればアップデートは完了です。

いったん端末から基板を取り外したあと、適当なケーブルで START と GND をショートしながら改めて接続します。ブラウザから 192.168.7.1 にアクセスすると GP2040-CE の Web Configurator が表示されます。

次の箇所を変更します。
- Settings > Input Mode: PS4 / Arcade Stick
- Configuration > Add-Ons Configuration > PS Passthrough: D+ 27 / D- 28 /5V -1 / Enabled
これで GP2040-CE の設定は完了です。
動作確認
はんだ付けしたベース付きポストにケーブル付きハウジングを挿し込み、G+/G-/GND をネジ端子付き USB ケーブルに接続します。5V のケーブルも接続する必要がありますが、Rasberry Pi Pico の GPIO ピンは 3.3V なのでピン番号 26 に接続されている黄色のケーブルは使えません。5V が供給されているターミナルブロックから配線します。

https://datasheets.raspberrypi.com/pico/pico-datasheet.pdf
この USB ケーブルをパネルマウントソケットに挿し込み、ソケットの逆側には RAP.V の USB ケーブルを挿し込みます。
USB-C ケーブルは PS5 に接続します。上の画像では 1P と GND を黒のケーブルでショートしていますが、すでに Web Configurator で Input Mode を PS4 に設定しているので不要でした。
はじめは PS5 に接続してもなにも反応がないので不安になりましたが、PS5 にコントローラーとして認識させるには PS ボタンを押す必要があることを思い出して、ターミナルブロックの HOME (PS) にケーブルを接続して GND とショートさせたところ、無事に認識されました。

これで基板の準備は完了です。次回は外装の加工について書きます。
改造レバーレスの基板を換装した (作業計画編)

これまでのあらすじ
前回、次のように書きました。
ところが Mayflash F500 では上記いずれのモードでもこの特殊入力を実現できません。
- X/Y: 1P 側の場合は右下、左下、右下と入力されて成立。2P 側の場合は左下、左下、右下と入力されて不成立 (省略)
特殊入力はとても便利なので、次のステップでは基板を交換する予定です。
予定通り基板を換装したので、備忘を兼ねて作業内容を書き留めておきます。長くなるので今回は作業計画について書き、残りは以下のように分けて書きました。
- 作業計画
- 改造レバーレスの基板を換装した (基板準備編) - garbagetown
- 改造レバーレスの基板を換装した (外装加工編) - garbagetown
- 改造レバーレスの基板を換装した (配線準備編) - garbagetown
- 改造レバーレスの基板を換装した (組み立て編) - garbagetown
電子工作素人おじさんがインターネット上の知見をかき集めて試行錯誤しながら作業した記録であり、目新しい内容はありません。それどころか、不正確、不合理、非効率な内容が含まれる恐れがあります。あらかじめご了承ください。
Pico Fighting Board
前回、次のように書きました。
このような事情からなかなかレバーレスに挑戦できない日々を過ごしていたところ、職場のなんでも知っているおじさんから Raspberry Pi にオープンソースのファームウェアを書き込んだ安価な基板でも RAP.V に認証をパススルーできるようになったことを教えてもらいました。 (省略) さらに幸運なことに、なんでも知っているおじさんからファームウェアをアップデートすれば RAP.V に認証をパススルーできることを教えてもらいました。
たまたま Mayflash F500 の基板がパススルーに対応していたので流用しましたが、上述の通り特殊入力に対応していないことが分かったので、当初の予定通り Raspberry Pi にオープンソースのファームウェアである GP2040-CE を書き込んだ基板を使うことにします。
ひとくちに Rasberry Pi と言っても、GP2040-CE のダウンロードページを見れば分かるように様々な種類がありますし、これらの基板に直接はんだ付けしなくても配線できる拡張ボードが存在します。
今回はこれらのうち、インターネットで情報が多く見つかる Pico Fighting Board (以下、PFB と略記) を使うことにしました。PFB の詳細は次のサイトが詳しいです。
次のサイトのように部品を買い集めて自分で実装することもできますが、自分にはハードルが高いので、メルカリで見つけた実装済みの品物を買うことにしました。

Mayflash F500
移行先の基板が決まったので、移行元である Mayflash F500 (以降、F500 と略記) の基板を改めて確認します。
中央上部から時計回りに四つの基板があり、それぞれの役割は次のとおりです。
- 中央上: LED 制御
- 右上: ディップスイッチと特殊ボタンの入力制御
- 右下: USB, マイクやイヤフォンなどの入出力制御
- 中央下: メイン基板
LED を制御する必要はないので、中央上の基板は取り外してしまいます。
同様にディップスイッチを制御する機能も必要ありませんが、PS ボタンなどは必要なので、右上の基板は残します。
回路を見ると向かって右から TPAD, GND, PS, SELECT, TURBO ボタンが配線されていることが分かります。TPAD は回路が途切れているように見えますが、基板の裏側で回路がつながっていました。GND はどこにもつながっていない、いわゆるベタというやつと理解しました。

引き続き RAP.V にパススルーするので USB ポートは必要ですが、筐体全面にポートがあると不便なので背面に移設します。フラットケーブルが短く背面からメイン基板までは届きそうにないことなどから、右下の基板は流用せずに取り外すことにしました。
当然ながらメイン基板も取り外します。PFB のピンマッピングと見比べながら、流用できる部品と用意しなければならない部品を検討します。
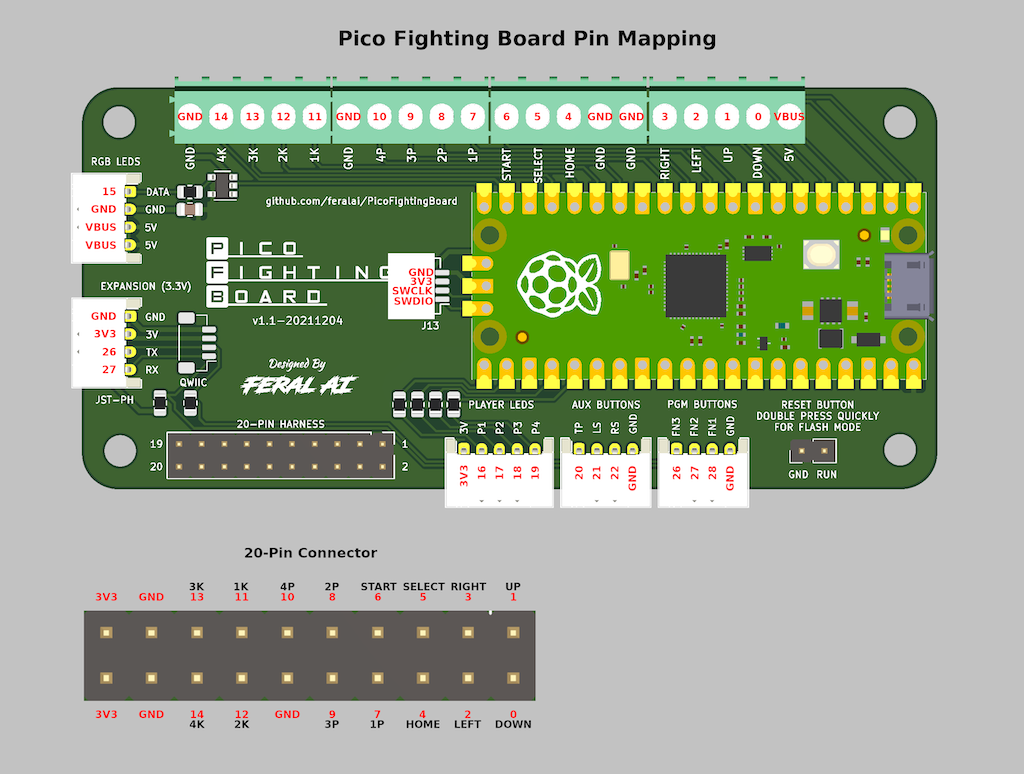
USB ポートの位置が違うのでおそらく F500 V2 という別機種と思われますが、次のサイトが参考になりました。
Mayflash f500 to Hitbox conversion guide (Parts list + Pics)
byu/b_Lurkn infightsticks
中央上にある START ボタンと移動および攻撃ボタンからそれぞれ二本ずつケーブルが伸びており、F500 の PH コネクタに接続されています。つまり、各ボタンごとに GND が必要です。PFB 上部に実装されたターミナルブロックには各ボタンに対応したピンがあるものの、GND は 4 つしかないので、チェーン配線にした GND ケーブルを用意する必要があります。
PFB のターミナルブロックには SELECT, HOME (PS) も用意されていますが、TPAD は PFB 下部に 4 ピンコネクタのピン番号 20 として用意されています。購入予定の PFB にはベース付きポストも実装されているので、ハウジングだけ用意すれば良いです。
USB ポートは筐体背面に移設することにしたので、パネルマウント型の USB ポートが必要です。また、パススルー用に配線する必要がありますが、購入予定の PFB にはピン番号 27, 28 に接続できるベース付きポストが実装されていないので、はんだ付けする必要があります。
メイン基盤と PFB のネジ位置が違うので、スペーサーなどで取り付け位置を調整する必要もあります。
最後に PS5 と接続する USB ケーブルを考えます。F500 のケーブルはメイン基板に 5 ピンコネクタで接続されている一方、購入予定の PFB には USB-C ポートが実装されています。既存ケーブルを加工して USB-C 端子を取り付ける方法も検討しましたが、USB-A から USB-C への変換などがむずかしそうに思えたため、既製品を購入することにしました。
買い物リスト
作業計画が決まったので、必要な物品をリストアップして終わります。
| 物品名 | 用途 |
|---|---|
| Pico Fighting Board | 特殊入力に対応した基板に換装する |
| ケーブル | チェーン配線 GND ケーブルを作る |
| ファストン端子 | 同上 |
| ファストンカバー | 同上 |
| ファストン端子圧着工具 | 同上 |
| 4 ピンハウジング | TPAD ボタン、パススルー用 USB ケーブルを接続する |
| パネルマウント USB-A ソケット | パススルー用 USB ポートを背面に移設する |
| 5 ピンネジ端子付き USB-A ケーブル | 同上 |
| ステップドリルビット | 筐体背面にパネルマウント用の穴を開ける |
| 4 ピンベース付きポスト | パススルー用 USB ケーブルを接続する |
| はんだこて | 同上 |
| はんだこて台 | 同上 |
| 糸はんだ | 同上 |
| スペーサー | 換装した基板を外装に固定する |
| USB-A to USE-C ケーブル | 換装した基板を PS5 に接続する |
PS5 で格ゲーを遊ぶためにはんだこてを買うことになるとは夢にも思っていませんでした。次回は基板の準備について書きます。
中古のアケコンをレバーレスに改造した
これまでのあらすじ
前回、次のように書きました。
あとはアーケードコントローラーをいい感じに片付けられれば完走です。どんな方法があるか、引き続き楽しみながら検討していきたいと思います。
最終的に薄型レバーレスに移行する方法が考えられます。最近では一万円台の製品も発売されるようになってきましたが、安価な製品のほとんどは PC では動くものの、PS5 では動きません。コンバーターを挟むことで PS5 でも動くようになりますが、コンバーターそのものがそれなりに高価です。
/Macに対応 有線アーケードコントローラー用【公式正規品】")
既製品が高くて買えないなら作ればいいわけですが、PS5 に対応した基板がこれまた高価です。

PS5 でも動作する RAP.V が手元にありますが、レバーレスが手に馴染まなかったことまで考えて元に戻せるよう改造できるか自信がありませんでした。
このような事情からなかなかレバーレスに挑戦できない日々を過ごしていたところ、職場のなんでも知っているおじさんから Raspberry Pi にオープンソースのファームウェアを書き込んだ安価な基板でも RAP.V に認証をパススルーできるようになったことを教えてもらいました。
PS4 and PS5 compatibility via USB passthrough authentication (PS5 support only as a legacy PS4 fightstick, not native). T
これを使えば安価にレバーレスに挑戦できそうです。いきなり自作にチャレンジするのはハードルが高そうだったので、まずは格安の中古アケコンを手に入れて改造するところから始めることにしました。
Mayflash F500
いざ中古アケコンを探し始めると、いろいろなパターンがあることに気付きます。
- RAP.V のように PS5 で動作するもの
- PS5 で動作しないが外装とボタンは流用できるもの
- PS5 で動作せず、ボタンも基板に半田付けされており流用できないもの
上記 1 はそれなりに見つかりますが、当然ながらとても高価です。レバーが取れてしまったジャンク品が見つかれば理想的でしたが、見当たりませんでした。
上記 3 もそれなりに見つかりましたが、流用できるものが外装だけになってしまうのでコスパが良くありません。
上記 2 を目当てにメルカリを検索する日々を送り続けたところ、ボタンが 3 つ動かなくなってしまった Mayflash F500 が出品されました。
![Mayflash USB ジョイスティック F500 PS4/PS3/XBOX ONE/ XBOX ONE S/XBOX 360/PC/Android/Nintendo Switch/Neogeo mini対応[日本正規品]](https://m.media-amazon.com/images/I/41pAD1YNCDL._SL500_.jpg "Mayflash USB ジョイスティック F500 PS4/PS3/XBOX ONE/ XBOX ONE S/XBOX 360/PC/Android/Nintendo Switch/Neogeo mini対応[日本正規品]")
すぐに調べてみたところ、素直な内部構造でボタンも流用できそうだったので購入しました。
さらに幸運なことに、なんでも知っているおじさんからファームウェアをアップデートすれば RAP.V に認証をパススルーできることを教えてもらいました。
つまり、次のように接続すれば基板を換装する必要がありません。
[PS5] --(USB)--> [Mayflash F500 (ファームウェア V1.22 以上にアップデート)] --(USB)--> [RAP.V]
購入してから数日後に到着した Mayflash F500 は、R1, L1, L2 ボタンが接着剤のようなもので固着しており、押し込めませんでした。

筐体右側全体に粘着テープ痕のような汚れがありましたが、内部は無事でした。

改造
天板
天板は厚さ 3mm ほどのアクリル天板、アートシート、金属天板で構成されていました。本体とアクリル天板に磁石が仕込まれており、アートシートを挟み込む構造です。本体にネジ止めされている金属天板に移動用ボタンの穴を開けることはむずかしそうだったので、アクリル天板だけ流用することにしました。

一般的なレバーレスコントローラのように攻撃ボタンを直径 24mm のものに変更するには、アクリル天板をまるごと取り替える必要があります。今回は天板やボタンをできるだけ流用したかったので、攻撃ボタンは 30mm のままにしました。一方、一般的に 30mm にする上ボタンは、将来的に攻撃ボタンに転用することを考えて、今回は 24mm にしました。また、レバー用に開けられている穴がちょうど 24mm だったので、下ボタンに流用しました。
さまざまなアケコンをレバーレスに改造するテンプレートが公開されているので、Mayflash F500 用のテンプレートをダウンロードして GIMP で改変しました。
https://support.focusattack.com/hc/en-us/articles/207447753-Control-Panel-Templates
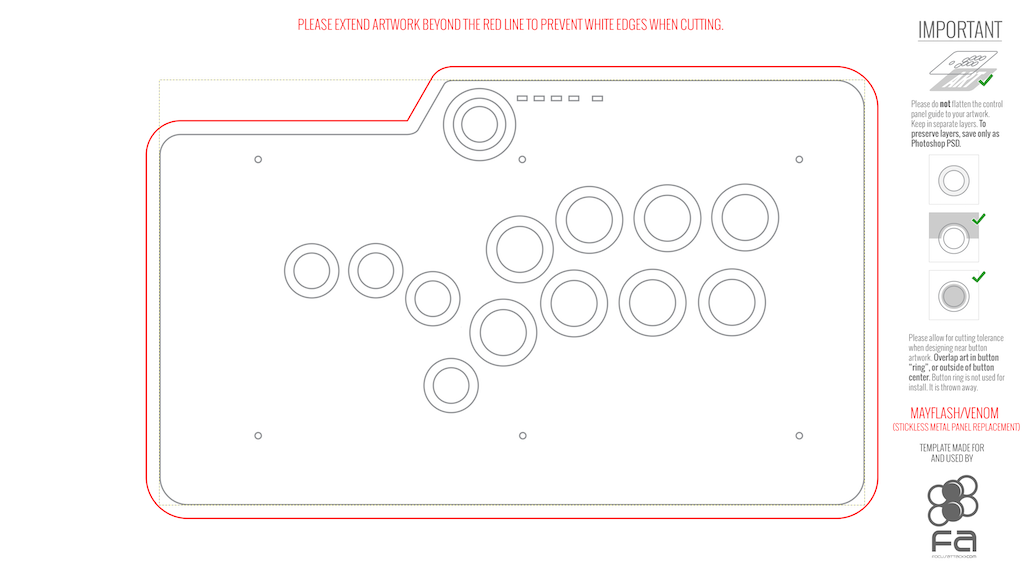
これを pdf に変換してコンビニで印刷し、位置を合わせてアクリル天板に固定します。GIMP で編集する際に中心を出しておくべきでしたが、印刷後に定規と鉛筆で対応しました。

ダイソーで買った適当な当て木を両面テープでしっかり固定してから、まず 3mm のドリルで中心を開けます。その後、メルカリで買った 24mm のホールソーで移動ボタン用の穴を開けました。アクリル板はそれなりに硬く熱に弱いので、最大トルクかつ低速でじっくり削るように気を付けました。貫通直後はバリが残っているためかボタンをスムーズに着脱できなかったので、丸棒ヤスリでバリを取りつつ穴を少し広げました。
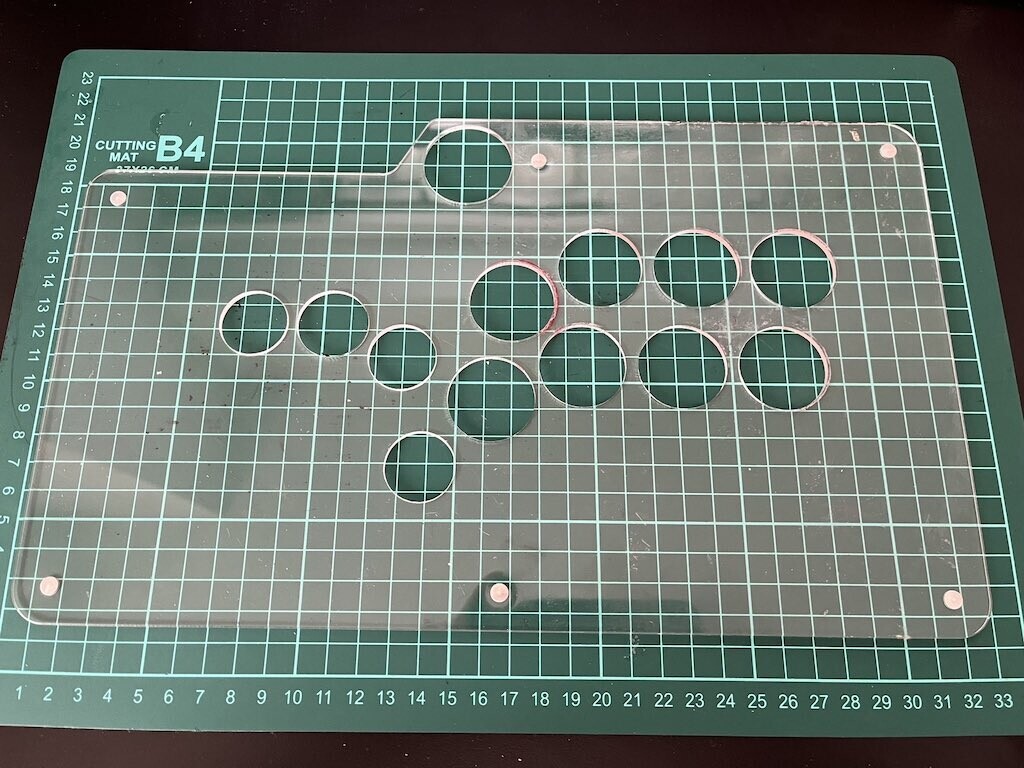
レバー
不要なのでレバーからケーブルを切断します。

ボタン
秋葉原の千石電商で買ってきたボタンをはめ込んだ様子です。移動用ボタンと L1 ボタンはふんぱつしてひとつ 450 円のクリアボタンにしました。R2 はひとつ 240 円のボタンにして、L2 は押さないので目隠しキャップを付けました。

外装
粘着テープ痕のような汚れは無水アルコールや中性洗剤でも取れなかったので、セリアで買った 600 番の紙やすりで削り落としたあと、メラミンスポンジで磨きました。

アクリル天板の汚れを透明なまま取り除くのはむずかしそうだったので、開き直って全体的に半透明になるように磨きました。

ファームウェア
アーケードコントローラーを USB 接続できる Windows PC を持ち合わせていないので、近所に住んでいる大きいお友達の家に押しかけて V1.28 にアップデートしました。
配線
最後に配線です。ボタンにケーブルが接続されてさえいれば動作しますが、例えば結び付けただけではプレイ中に脱落する可能性がありますし、かと言って半田付けしてしまうとボタンを交換する際に半田を取る必要があります。
そのため、一般的には次の手順でケーブルにファストン端子を圧着して、これをボタン側の端子に差し込みます。
- ケーブルの被膜を 5~10mm ほど剥がして、露出した芯線をよじる
- ショート防止用ファストンカバーを差し込む
- ファストン端子を差し込み、芯線部分が確実に接触するように圧着する
- ケーブルが脱落しないように被膜部分をかしめる
- 別ケーブルの端子と接触してショートしないようにファストンカバーを戻す
単純なように見えますが、ケーブルはとても細く、ファストン端子はとても柔らかい金属なので、きれいに圧着するには相応の工具と技術が必要です。なんでも知っているおじさんから工具を借り、かつ使い方を教わるフリをして半分ほど圧着してもらいました。
 XH2.54/Dupont 2.54/2.8/3.0/3.96/4.8/KF2510/JST 端子クリンパー プライヤー ラチェットワイヤコネクタ クリンピングツール")
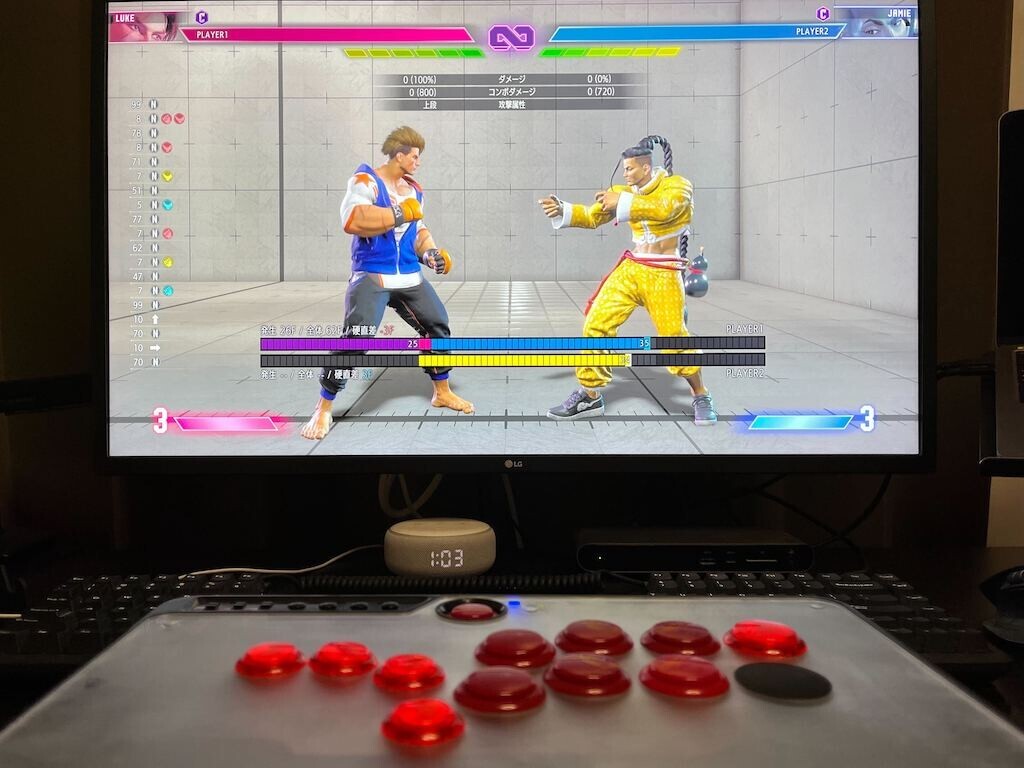
無事にファストン端子を圧着できたら、各ケーブルを正しいボタンに差し込んで完成です。どのケーブルがどのボタンに対応しているか分からなくなったので、コントローラーをゲーム機に接続してトレーニングモードを開き、各ケーブルをショートさせてどのボタンが反応しているか確認しました。

感想
とても楽しいです。
自分はレバーでは下から右に 1/4 回転するいわゆる波動拳コマンドはきれいに入力できる一方で、下から左に 1/4 回転するいわゆる竜巻コマンドをきれいに入力できません。具体的には、下ではなく右から始めて半回転したり、左で止まらず左上どころか上まで回ったり、左下が抜けてコマンドが成立しないことがよくあります。これを二回続けて入力するスーパーアーツが安定せずに困っていましたが、レバーレスではとてもきれいに入力できます。

レバーによるコンボ入力はアナログでコンディションに左右されやすく、昨日はできたコンボが今日はできないし原因も分からないということがよくありました。レバーレスは音ゲーのようにリズムでコンボを覚えていく感覚があり、コンディションに左右されにくい印象を持ちました。
課題
レバーでは物理的に不可能な左右や上下の同時入力について、コントローラーやゲーム、大会ルールで解釈が一致していません。ストリートファイター 6 の大会である Capcom Pro Tour では、左右や上下が同時に入力された場合はニュートラル扱いとするコントローラーを使う必要があります。
Mayflash F500 の基板はディップスイッチによりふたつのモードを切り替えられ、それぞれ次のように動作しました。
- X/Y: 左または上が優先。右を押しながら左を押しても、左を押しながら右を押しても左が優先される。上下も同様
- DPAD: 左右、上下ともにニュートラル
DPAD にすれば万事解決と思いきや、左下右の同時押しもニュートラルになってしまいました。

ここで話は少し逸れて、ストリートファイターにおける簡易入力について説明します。
例えば、右、真下、右下、パンチと入力するいわゆる昇竜拳コマンドがあります。このコマンドを正確に入力するのはとてもむずかしいので、それぞれ右要素、下要素、右要素が入力されていればコマンド成立と判断することを簡易入力と呼びます。例えば右下、左下、右下と入力しても成立するので、しゃがんだまま飛んできた相手をぎりぎりまで引きつけてから昇竜拳で落とすというテクニックがあります。
この簡易入力とレバーレスの同時押し入力を組み合わせた特殊入力というテクニックがあります。人間の指は離すよりも押すほうが簡単で速いという性質を利用したものです。
昇竜拳の場合、まず下と右を同時に押して右下を入力します。次にそのまま左を押します。このとき左右同時押しはニュートラルとなるため真下が入力されます。最後に左ボタンを離して改めて右下を入力します。結果として右下、真下、右下と入力されることになり、簡易入力として昇竜拳コマンドが成立します。
ところが Mayflash F500 では上記いずれのモードでもこの特殊入力を実現できません。
- X/Y: 1P 側の場合は右下、左下、右下と入力されて成立。2P 側の場合は左下、左下、右下と入力されて不成立
- DPAD: 左下右の同時押しがニュートラルとなり真下が入力されないので、1P/2P 側ともに不成立
特殊入力はとても便利なので、次のステップでは基板を交換する予定です。
PS5 を買って隠した
PS5 を買ってみたらデカくて邪魔だったので隠しました。
天板の材質にも依るだろうけどFlexispot 公式天板にネジ6本で止めるとかなりがっちり固定されてPS5程度の重量でマウントごと落下する不安はまったく感じない。マウントと本体も台座固定用ネジで止めるので本体がマウントから滑り落ちる心配もない pic.twitter.com/ILcha5d9ue
— がるがべさん (思秋期) (@garbagetown) March 20, 2023
これまでのあらすじ
これまでは、次の経緯で職場のガチゲーマー達から PS4 とアーケードコントローラーを借りてストリートファイター V をプレイしていました。
- 2018~2019 年頃はゲーム部活動と称して職場の会議室にゲーム機と酒を持ち込んで各自それぞれ好きなゲームをプレイしていた
- 2020 年頃から基本的に在宅勤務となりゲーム部活動はオンラインに移行した
- 自分はゲーム機を持っておらずストリートファイター V をプレイできなくなってしまった
- 2021 年頃から禁断症状に苦しむようになり、ゲーム機の購入を検討するも、課題が多く難航した
- ゲーム部活動がオフラインで再開できるようになるまで、誰も使っていない PS4 を持ち帰って利用して良いことになった
その後、アーケードコントローラーを買ったことは 2022-06-19 に書きました。
さらに 2023 年頃から少しずつ職場でのイベントが再開されるようになり、また PS5 の供給も安定してきたので、いよいよ本格的にゲーム機の購入を検討しました。
選定
2021 年頃とは大きく状況が変わっていたので、どのゲーム機を買うべきか改めて整理しました。
ゲーミング PC
高いです。職場のガチゲーマー達に軽く相談したところ、最低 20 万円、相場は 30~40 万円と言われて引きました。ゲーム以外にも使えるとは言え高過ぎます。PS4 で買ったソフトやコツコツ集めた DLC を移行できないのも大きなデメリットです。
PS4 より入力遅延が 2F ほど短い (1F は 1/60 秒) と言われていますが、そんなに高度なレベルでプレイしていない自分にはメリットになりません。
Steam Deck
2021 年頃には存在しなかった選択肢です。512GB $649, 256GB $529 は少し高いですが、64GB $399 なら手を出せる範囲です。
しかし、ソフトや DLC を移行できないデメリットに加えて、公式の Steam Deck 互換性確認状況が "確認済み" ではなく "プレイ可能" である点が気になりました。こちらのツイートに依ると ストリートファイター V はふつうに遊べるものの、IV はそもそも "未対応" で、無理やりインストールしてもネット対戦が動かないようです。
メイン種目、Steam Deck+モニタ出力(120Hz)でストVラウンジ
— RozeRoze (@RozenHorizon) March 5, 2023
結果としては"最高"でした、かなり快適に遊べます!
元々自分がSteam Deckに求めてたラインとしては「格ゲーオフ対戦/トレモができる」程度だったんだけど、USB Type-Cハブから有線LANと画面出力すれば熱帯もフツ~に快適に遊べてビックリ pic.twitter.com/E78cLzcKRN
Steam Deck第二のメイン種目、ウルトラストリートファイターIVの検証結果です
— RozeRoze (@RozenHorizon) March 5, 2023
……残念ながら、そもそもの表示が「非対応」という出オチ
でもインストールは可能だったので表示は無視してそのままインストール&起動してみる pic.twitter.com/aYCHFKH5jJ
PS4
メルカリで新品未使用が激安で手に入るなら検討の余地はあると考えて探してみたところ、相場は 30,000~40,000 円程度でした。PS5 が 50,000~60,000 円で買える世界線で選ぶには少し高いと感じました。
PS5
ディスクトレイがついた通常盤が 60,000 円、ソフトをダウンロードしてプレイするデジタルエディションが 50,000 円程度です。ふつうに考えればとても高価ですが、ゲーミング PC や Steam Deck と比較するとお手頃に感じてしまいます。
ディスクで買った最新タイトルを速攻でクリアしてメルカリやゲオに循環する戦略を取る場合や、Ultra HD Blu-ray で映画などを視聴する場合は通常盤を選ぶことになるでしょう。自分はストリートファイターシリーズをちまちまやり続けるか、セールになった旧タイトルをプレイできれば良いので、デジタルエディションを選びました。
購入先はポイントなどが利用できるアマゾン一択です。招待販売に申し込んでから 3 週間程度で招待メールが届きました。
ドーン pic.twitter.com/ss7L8QACpv
— がるがべさん (思秋期) (@garbagetown) March 12, 2023
課題
先日の記事 に映り込んでいる通り、PS4 は黒いデスクに平置きして使っていました。次の理由からこの位置に PS5 を置くことはできません。
昇降デスクを使っているので、足元に置くと HDMI ケーブルの取り回しに頭を悩ませることになります。そこで PS5 をデスクにマウントする方法を探し回り、最終的に Monzlteck の製品を選びました。

{kind=link}
椅子の肘掛けなどがぶつからないよう、デスク奥側の天板にマウントしています。電動ドリルと 2.0mm のドリルビットがあれば簡単に取り付けられます。6 本の木ネジでがっちり固定するので落下の不安は感じません。
Flexispot の昇降デスクであれば中央のビーム部分に前面の USB-A ポートが干渉することもありません。通常盤をマウントしてもディスクトレイは使えると思います。
完璧。昇降デスクのビーム部分に干渉しそうで心配だったUSB-Aポートもちゃんと見えるのでアケコン接続も問題なし。
— がるがべさん (思秋期) (@garbagetown) March 20, 2023
排気口が電源アダプタなど詰め込んだ自作ケーブルラックに向いているので排熱には少し気を付けながら使ってみる pic.twitter.com/figgXePKGA
余談
引き続きメルカリの売上金を持て余しており、上記 Monzlteck のマウント製品もできればメルカリで購入したいと考えて探しましたが、残念ながら出品されていませんでした。
そこで、アマゾンの支払いにメルカリの売上金を使えないか調べたところ、3 つの方法があることを知りました。
メルカリを長く使い続ける場合はポイントがつくメルカードを発行すると良さそうです。自分はメルカリの売上金を消化することが目的なので、メルペイのバーチャルカードをアマゾンに登録して支払いました。
まとめ
2021-09-27 に次のように書きました。
さらにデスクの上をすっきりさせるには PS4 とアーケードコントローラーを片付ける必要があり、次のような妄想をしています。
- PS4 はデスク天板の裏に固定する
- アーケードコントローラーは天板裏に引き出しを付けて収納する
- レバーが邪魔なのでこれを機にヒットボックスに乗り換える
しかしながら上記いずれも職場の格ゲーガチ勢から無料で借りているものなので、まずは自分で買い直すところから始めなければならず、道のりはまだ遠そうです。
あとはアーケードコントローラーをいい感じに片付けられれば完走です。どんな方法があるか、引き続き楽しみながら検討していきたいと思います。